The Postman request:
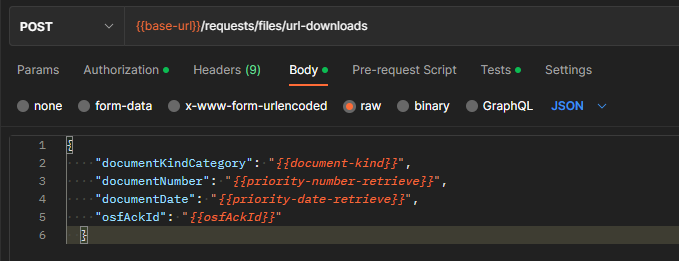
Request configuration
a.- Headers
Standard headers, nothing to update here.
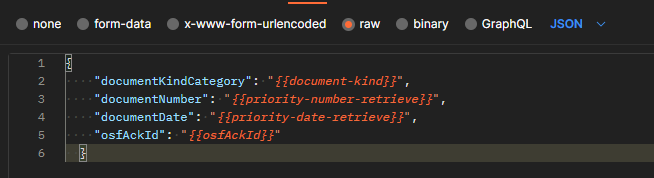
b.- Body
Values that are used for this demo (selected as Postman type RAW):
Key | Value | Notes |
|---|---|---|
| documentKindCategory | "{{document-kind}}" | Document type, from "design, patent, trademark, utility model", for this example "patent" |
| documentNumber | "{{priority-number-retrieve}}" | priority number used before (to be sure that is in the system, in this case it was generated during the 1.1.1.1.- getToken (POST) request |
| documentDate | "{{priority-date-retrieve}}" | priority date used before (to be sure that is in the system, in this case it was generated during the 1.1.1.1.- getToken (POST) request |
| osfAckId | "{{osfAckId}}" | Acknowledgment Id required to download the file, obtained during b.2.1.2.- POST retrieval |
c.- Pre-request script
Is not used for this request
d.- Tests script
The following script is executed after the request is sent, to evaluate the response and also to set up environment variables (if they are needed for following requests)
Expected response
e.- Body
The json will provide the url to download the file(s) available for the requested record.
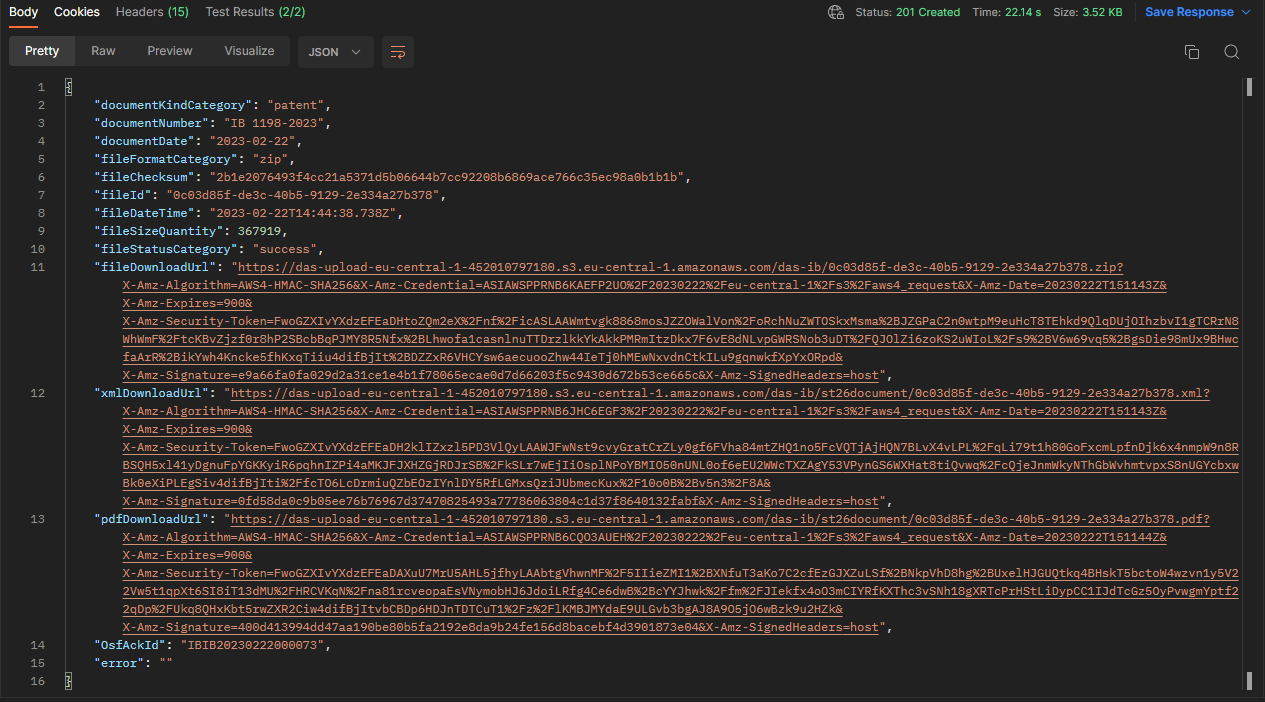
If you click on the individual URL, you will be able to download the files available for the current record (the full zip, the pdf file and the xml file):
![]()
f.- Headers
Normal headers.
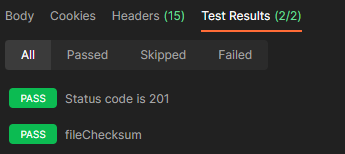
g.- Test results
This depends on the test we set up in the test script